
Systems Across Domains
Why cross-domain systems understanding matters, and a library of system-domain notes.
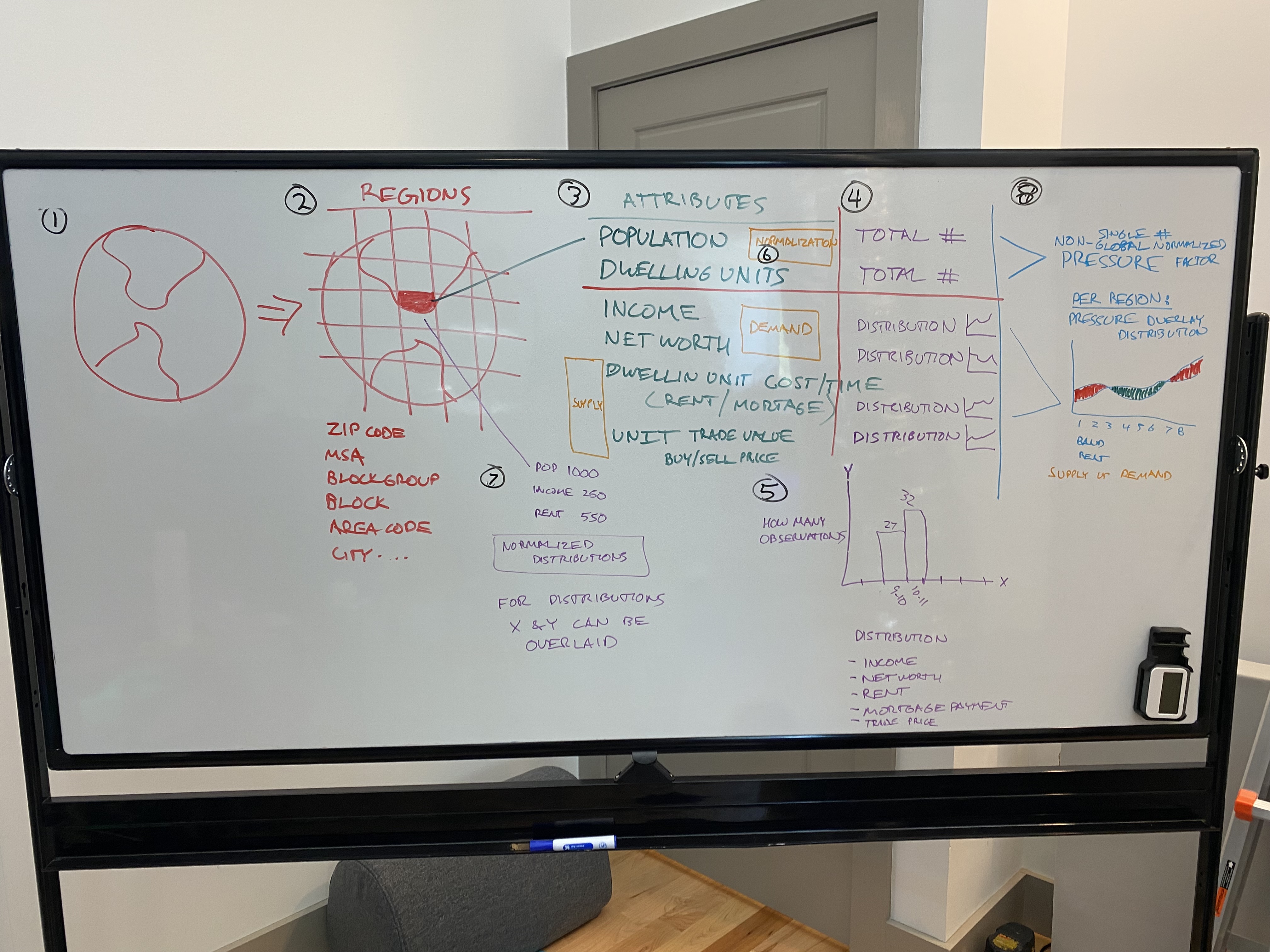
Data Warehousing
Data Warehousing is the storage and management of large datasets optimized for reporting and analysis.
Data Warehousing is the storage and management of large datasets optimized for reporting and analysis. On this site, it matters because it transfers across technical, operational, and venture work instead of staying trapped in one narrow context.
Learn more: https://en.wikipedia.org/wiki/Data_warehouse
Why cross-domain systems understanding matters, and a library of system-domain notes.

Automated processes incorporate human judgment to improve accuracy, safety, and outcomes.
Compute systems are optimized for executing trained models efficiently at scale.
Storage layers retain raw and structured data at scale while bridging analytical and operational workloads.
Centralized repositories optimized for analytical queries are structured around schemas that support aggregation, reporting, and historical analysis.
Pipelines extract, transform, and load data across systems while enforcing schema, quality, and timing constraints.
Pipelines train models on data to produce predictive or generative outputs and improve performance through iteration.
Event-driven architectures process continuous data flows in real time to support reactive systems and low-latency analytics.
Projects building data pipelines, warehouses, lakes, and large-scale analytics infrastructure.
Abstract representations of entities and relationships are structured for efficient storage, querying, and interpretation.